|
Goal
Automatic speech recognition (ASR) systems, such as ViaVoiceT, and DragonDictate ® are being used more frequently by the general population and individuals with physical disabilities. While there has been major improvement in ASR, commercially-available systems do not work well for individuals with dysarthric speech. Our goal is to build a portable system with text and/or speech output to recognize dysarthric speech.
Progress to Date
Speech samples are collected at Duke University Medical Center and the Center for Applied Rehabilitation Technology (CART) at Rancho Los Amigos National Rehabilitation Center in Downey, CA, encrypted and sent electronically to our Federal Laboratory Consortium partners at NavAir, in Orlando, FL. Using the speech samples, the engineers at NavAir create speaker independent Automatic Speech Recognizer (ASR) models that are returned and evaluated by dysarthric speakers at Duke University Medical Center and the Center for Applied Rehabilitation Technology (CART) at Rancho Los Amigos National Rehabilitation Center in Downey, CA.
Voice samples have been collected from human subjects with speech impairments including spastic, flaccid, and mixed dysarthria. Subjects need to be literate; therefore we have focused subject recruitment on subjects with dysarthria secondary to ALS. Many individuals with ALS do not experience cognitive impairment that is common with for example, Multiple Sclerosis or Parkinson’s disease.
Subjects read digits 0 to 9 which are written out (e.g. EIGHT, FOUR, ZERO) while sitting in front of a computer monitor while wearing a light, head mounted microphone. Subjects read one hundred “zip codes” that are simultaneously recorded by a computer. Voice samples are verified by Duke researchers for completeness and accuracy and are then sent to NavAir to be built into ASR models. ASR models are built by NavAir and returned to Duke University Medical Center. Models are evaluated by standard internal methods for overall percentage word recognition correctness as determined by the following formula:
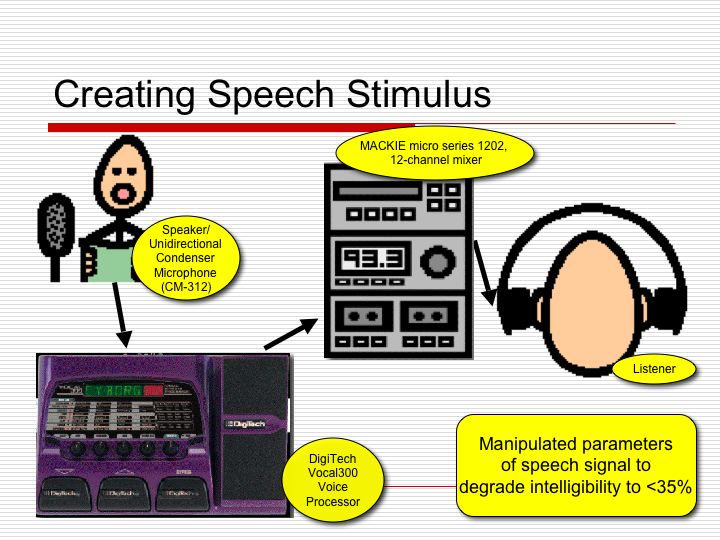
Much of the research effort has focused on the collection of speech samples. The original equipment used to collect samples consisted of a Sun SPARCstation 20 running UNIX, connected to a studio quality, ART TubAmp preamplifier with a Shure SM-10A headset microphone. This system had been used for several years in the Navy’s research due to its superb signal to noise ratio. Several clinical and technical challenges we encountered in collecting data using the Sun setup including difficulty transporting the equipment and difficulties transferring data from the computer to removable media for transfer to Orlando. Because of these technical issues, the system was ported from a UNIX native scripting language to Red Hat Linux. The Linux system runs on an IBM Thinkpad 390 laptop system with an Intel Pentium II 300 MHz processor and 256 MB ram. In order to ensure good quality recordings, an external sound capture device was needed. An Eridol, UA-1A audio capture device by Roland was chosen and configured for use with the Linux system. The UA-1A is a USB device that is recognized by Linux. The system is completed using the ART TubAmp preamplifier and Shure SM-10A headset microphone.
Most recent recording have be made using an IBM Thinkpad X41 running a user friendly, custom built, data collection program written in the JAVA language. JAVA enables the application to be run on standard windows PCs running windows XP using standard internal soundcards. Again, the ART TubAmp preamplifier and Shure SM-10A headset microphone were used. Several pilot data sets of typical, non-dysarthric speech have been collected using the new data collection systems. ASR models have been built from these data sets and have been evaluated. The ASR models built from data collected on the new hardware platform perform at a level comparable to the Sun system. Word recognition rates for the pilot data of typical speakers are at or above 95%.
 .jpg)
Results
To date a total of 50 sample sets have been collected from 29 females with dysarthria and 21 males with dysarthria. This data has been used to create the first set of computer acoustic models based on dysarthric speech samples. ASR models are created from a subset of 80% of each sample set and tested or “exercised” with the remaining 20%. Navy researchers report the initial correctness numbers are historically where we would expect them to be. Results for the first 4 models created are summarized in the table below:
|
Model
|
Word Recognition
|
| Female Mild |
86.24%
|
| Female Moderate |
70.27%
|
| Male Moderate |
75.38%
|
| Female Severe |
51.25%
|
While the results from the models are lower than expected, the pattern of decreasing word recognition percentage with increasing dysarthria is expected and demonstrates the models represent the data. The 86% word recognition rate for the Female Mild model and the rates for the male and female moderate models are in line with the initial performance of off-the-shelf ASR systems as reported by Koester (6), while the Female Severe word recognition of 51% is better than random and shows correlation. Additionally, these models are raw and have not been tuned. We expect that tuning the linguistic model to the acoustic model, as is common practice in ASR systems, will improve the recognition rates.
There are significant challenges surrounding the collection of speech data from individuals with speech disabilities. Speech disabilities are often secondary to conditions that affect motor, sensory and cognitive abilities. This can make it difficult for subjects to travel to research sites, see and hear stimuli, or even understand or read instructions. In this study subjects with dysarthria secondary to ALS were chosen specifically because ALS does not generally affect sensory or cognitive abilities. Associated motor impairments did require the development of portable data collection systems enabling researchers to go to the subject, rather than have the subject come to us.
In speech recognition research and development, speech data bases are closely guarded and if available are expensive and only reflect typical speech. We are working towards making the existing dysarthric speech database freely available for research purposes.
Presentations
Caves, K., Boemler, S., Cope, B. “Development of an Automatic Recognizer for Dysarthric Speech.” Presented at the ALS/MND International Conference, Toronto, ON, Dec, 2007.
Caves, K., Boemler, S., Cope, B. “Development of an Automatic Recognizer for Dysarthric Speech.” Presented at the RESNA Annual Conference, Phoenix, AZ, June 2007.
Caves, K., Chitty, J. “Assistive Technology Update” Presented at the Duke University Medical Center Neurology Grand Rounds, Durham, NC, March, 2007.
Shane, H., Boemler, S., Caves, K. “Using Automatic Voice Recognition with People With Dysarthric Speech.” Presented at the ATIA Meeting, Orlando, FL, January 2003.
Caves, K., (2002). “Interface Development at the AAC-RERC”. RESNA News, Summer 2002, pp. 4-5.
Caves, K., Shane, H., Boemler, S. “The application of a new model of pattern recognition for movement analysis and speech recognition.” Presented at the Assistive Technology Industries Association Meeting, Orlando, FL, January 2002.
For more information about this project, contact Kevin Caves.
|